A simple example: processing a compressed data file accessed via HTTP (could be API, static website, or any other HTTP source).
I don’t actually care what language, stack, library or framework, etc. Mostly, I don’t care because it doesn’t matter. This problem isn’t about coding, its about performance. So, for the sake of the example, assume the language is fast and the library or framework it uses is exceptional.
Now, the normal approach is this:
- Fetch the compressed file
- Decompress the compressed file into a source file
- Process the source file
This is great, except it takes longer to fetch the file than we’re allowed to wait to start processing the data. And that ignores the decompression time. In short, we have a performance problem. We need to begin showing the results before the bandwidth we have finishes delivering the compressed file.
Well, if it takes 30 seconds to move the data through the wire and we must start showing results within 5 seconds, I guess we’ll need a faster pipe.
Or perhaps we can just do better…
The Problem in Images
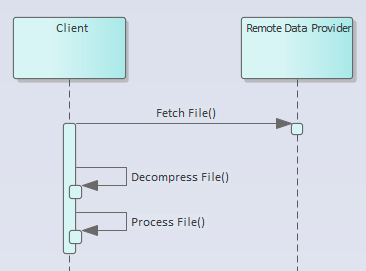
So, to determine the time, add up the duration of each of the three tasks. If Fetch File takes 30 seconds, then no matter how much we optimize Decompress File and Process File, we’re not going to make our 5 second goal.
This is because, obviously (and this is where all the warning bells should be going off) this is a sequential process, in which later steps are wholly dependent upon earlier steps.
Hence, the proposal to management: we need a faster pipe.
It’s a Good Thing Computers Don’t Know What’s Obvious
What to do, what to do?
There are reasons that experience helps. Today, it’s a given that a Web Service is called and the result is provided. However, under the covers, that’s not actually a synchronous task. In actuality, the pulling of data is an interaction of at least four transmissions from client to server. And the server can actually stream in as many messages as needed.
Part of this is the three-way TCP/IP session establishment handshake. And that assumes the IP address is known. It might require even more transmissions if DNS resolution is needed and the resolver hasn’t already cached the domain name requested.
Why bring those things up? Because they show that the view in the image, the view of the high-level coder, is in fact not real. It’s a “fiction”, a “model”, that we all choose to believe is true because it reduces the cognitive complexity. But the reality is, what is happening when we request that compressed file is not an atomic step.
What’s happening is more complex. And that’s our edge.
Why Performance Engineering is Hard
So, we have a performance challenge. We need to get results in 5 seconds from a process that takes no less than 30 seconds just to fetch data.
What’s actually happening when we do Fetch File?
Here is what goes on under the covers during the CALL to fetch the file via the API:
- Name resolution for the URL’s host name portion
- TCP three-way handshake to open a socket to the IP address that the URL name represented
- Client sends (via the HTTP protocol) the request (assume GET)
- Server accesses the resources referred to be the URL (assume a filename of a compressed file)
- Server sends HTTP header data
- Server sends HTTP content data (the compressed file)
- Client receives HTTP header data
- Client receives start of content and creates file for storing bytes
- Client receives compressed bytes and appends them to file
- Client recognizes end of compressed bytes and closes file
- Client returns to caller
There are many other steps, but these are the important ones.
Now, depending on the settings, we could have the client request to decompress the file in the protocol handling code. If so, then 9 becomes: Client receives compressed bytes, decompresses them, and appends them to file.
That change, by telling the client library to decompress the result, removes the entire Decompress File from the diagram.
Of course, the client doesn’t return to the caller in step 11 until the 30 seconds has elapsed, so the problem remains. We can reduce the client’s number of steps outside the API by one, but we don’t reduce the performance overhead much.
Note, this is not to say we don’t improve the performance at all. By decompressing in memory and writing the decompressed file we avoid create/write/close of the decompressed file. It’s a real gain and it also reduces the disk space needed. It’s a useful step in many cases. It simply doesn’t help us here.
In short, we can’t fix the problem of taking 30 seconds to fetch the file (even if we can reduce or eliminate the next step) so long as steps 1 through 11 are considered atomic.
So, let’s give up atomicity.
From Atomic to Streaming
The reason we have a 30 second delay is the movement of the compressed bytes to receive the entire copy from server to client before processing.
Why? Why do we want the entire file?
Sometimes, we do need the whole file before we can do anything. But I very carefully said “start” showing results, not show the full result.
Since I haven’t said what the data represents, lets assume it represents some form of telemetry. The data is compressed because it’s enormous, but the data is always a stream internally. The important aspect — we do not need later data in order to process earlier data.
If that’s not true, we can not stream regardless. We would have to manifest the entire set of data on the client before processing. THAT would mandate the full delay. An example of that would be a data file where the index to the data is APPENDED at the rear. Until the index is available, we can’t interpret the earlier bytes. ZIP files have their “central directory” at the rear, and may have non-compressed data surrounding the compressed portions (such as an executable self-extractor).
Thus, there is no general solution that says data can always be streamed.
However, many data layouts are in fact streamable. Meaning, they can be processed “record by record” as they bear. When computers had minimal RAM and were shockingly slow by modern standards, it was taught how to do streaming in COBOL (for example “sequential update logic”) and the reason for sorts that use multiple files as inputs and outputs is because there’s not enough RAM to load them and do in-memory sorts. Those are also setup to be streamed.
Today, with modern computing power and software tooling, there’s a tendency when learning to learn batch atomic instead of interactive streamed. The diagram was a simple batch atomic model. It’s also what is primarily taught.
But, let’s make the jump into streaming…
Streaming
It’s not enough to request a stream from a URL unless the library specifies that the stream is provided during the call and not after it.
For instance, a perfectly valid way to return a stream from a URL is to fetch the entire remote object into a temporary file, rewind it, and return a stream to the open temp file. The file will vanish when the stream is closed, so no cleanup issues. However, the 30 second delay will still be present.
You can find out if your language implementation actually fetches the whole thing before returning it by fetching a resource larger than your RAM. If an out of memory occurs when a stream is requested, the system is fetching entirely before providing access.
If the request immediately returns a stream and the connection to the server stays open until you start reading, then the stream is being given to you as it bears. In other words: you can freely process the data while it is being sent.
That is true stream processing, not laying a streaming API over a batch request.
In such a model, this actually happens (first seven steps the same):
- Name resolution for the URL’s host name portion
- TCP three-way handshake to open a socket to the IP address that the URL name represented
- Client sends (via the HTTP protocol) the request (assume GET)
- Server accesses the resources referred to be the URL (assume a filename of a compressed file)
- Server sends HTTP header data
- Server sends HTTP content data (the compressed file) — takes TIME and many physical writes
- Client receives HTTP header data (normally treated atomically!)
Up until now, those seven steps are the same as noted. I added comments on the end of steps 6 and 7, but the operation on the server and the handling of the HTTP headers is the same. The next steps are not the same:
- Caller to the URL fetch request returns a stream
At this point, the stream is to the internal buffer of the server. Depending on how the library is written, it could literally be the internal buffer. It could be a copy of what came from the server in a buffer. But the key is that the stream is not a stream to a block of data. It’s actually something that will block if there’s no data from the server yet and the server is still sending. It’s a true stream.
Normal processing on the stream will be blocking. The client-side processing is in parallel to the server streaming out the data. The server is still talking to the client library. But the user’s code is handling the data instead of the library writing bytes to a file while blocking.
Combining handling the stream with the library doing decompression in the protocol handler and the original task is no longer hard. So long as enough of the data arrives within 5 seconds to start presenting data our goal is met.
Conclusion
This particular example happened to be about performance. It’s a useful thing to understand for performance, but that’s not really the key takeaway.
The modern tooling we have is exceptional. It is setup to make easy things easy — it’s easy to fetch data from a URL. Anyone who has written web client tools without the modern tooling can appreciate how easy it is.
The problem we face with all the modern tooling is that too often the modern tooling makes the easy easy but makes the hard harder. A “naive” URL library will pull the whole data source before returning to the caller. It’s easy to write, it’s easy to understand. And for most cases it’s even sufficient.
It’s crucially important for someone who wants to do more than copy/paste from examples that they understand what’s actually happening in their libraries. Perhaps more importantly, it’s important to understand what’s happening in the machine, at the level of the assembly language, at the level of the IO processing, and so forth. And sometimes, (perhaps more often than is reasonable) debugging requires we examine what’s on the wire.
In embedded and hard real-time, we even need to examine the logic changes on wires and pins with oscilloscopes!
When the easy libraries and samples aren’t enough — well, that’s what makes it fun.
Keep the Light!
Otter
Brian Jones
